文章目录
- 备份导出数据
- 方案一:支持可以整个库导出、部分表导出、多个库导出(可选格式较少)
- 使用连接数据库
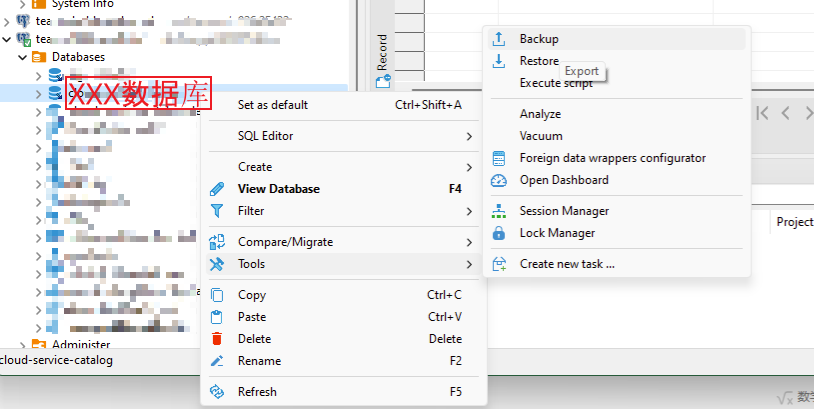
- 鼠标右键选择需要导出备份的数据库-工具-备份
- 勾选需要导出的表-点击下一步
- 设置输出目录和输出名称-点击开始
- 导出成功
- 方案二:导出备份单个表,以各种格式(可选格式较多)
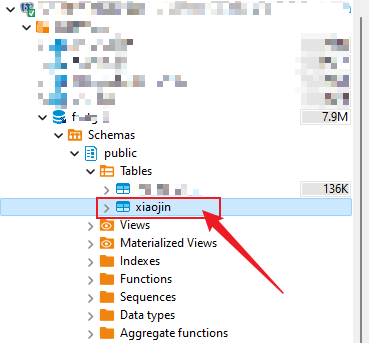
- 选中某个表,单击鼠标右键-导出数据
- 选择你喜欢的格式
- 配置导出参数-自己配置哇~~
- 执行导出
- 导出成功
- 导入、恢复数据
- 方案一:适合数据量小的情况
- 新建数据库,设置数据库名
- 使用SQL编辑器进行创建表结构和数据导入
- 执行语句
- 创建成功
- 执行插入数据语句
- 方案二:批量导入单个数据库的多个表(会导致之前表数据被完全替换掉哦,注意提前备份数据)
- 如果新的服务器没有这个数据库,先创建数据库
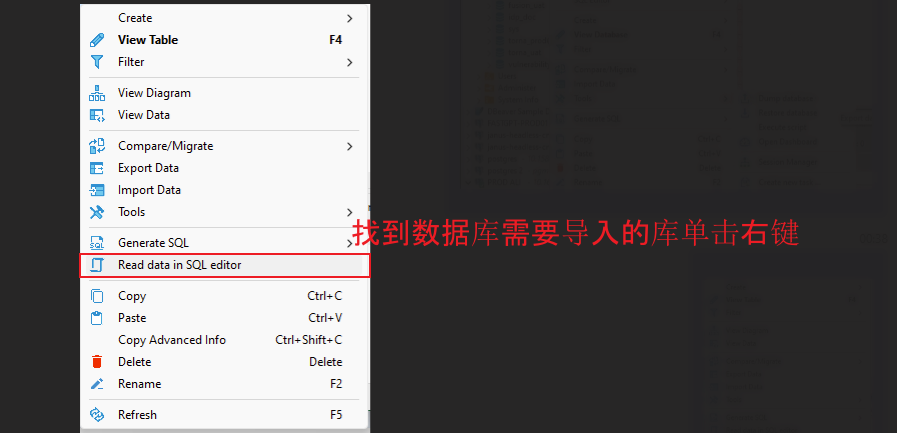
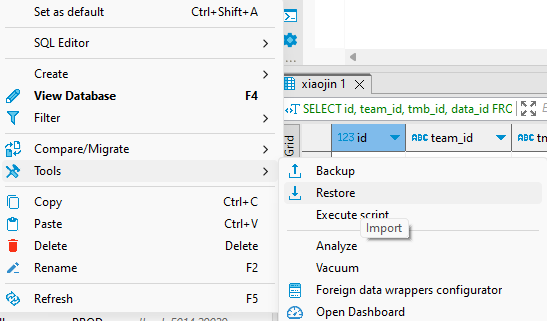
- 右键点击需要导入的数据库-工具-导入
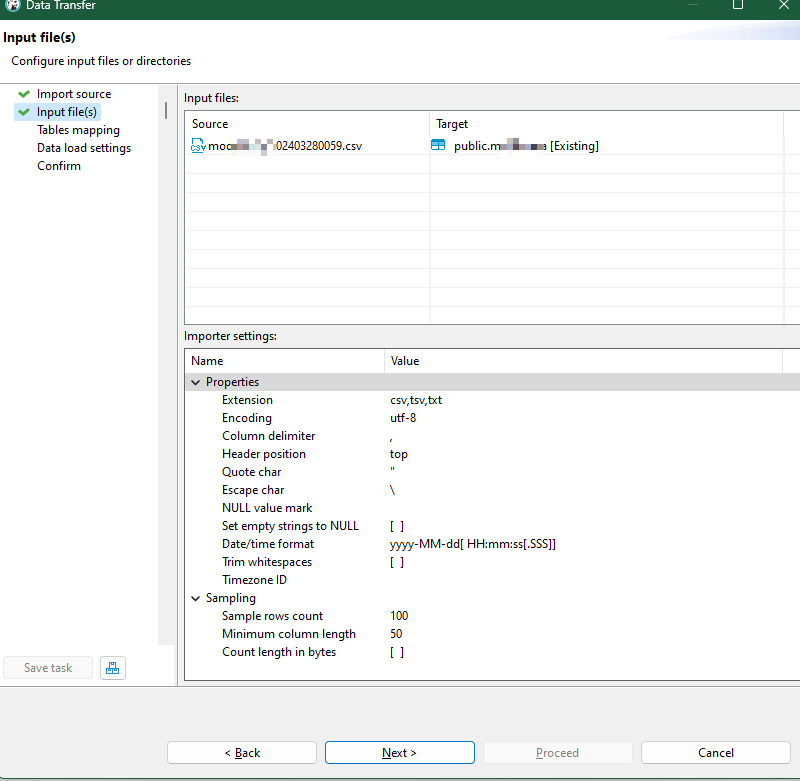
- 选择需要导入的文件
- 执行文件,导入成功
- 方案三:单个导入某个表
- 选择需要导入的表,备份表
- 选择需要导入的表,点击右键-导入数据
- 选择你文件的格式
- 执行导入
- 导入成功
- 方案四:导入大文件
- 使用vscode打开需要导入的文件,确定我们准备的SQL文件编码格式
- 点击项目
- 打开存放Scripts的文件夹,将我们的.sql拖进去
- 右键刷新
- 右键-属性-检查格式
- 关联数据源
- 停留在项目下-连接-找到关联的数据源-右键-创建执行数据库任务
- 填写任务名称,选择执行脚本
- 添加脚本
- 执行成功
- 方案五:最简单的执行sql方案(支持大文件)
- 选择项目-找到需要导入的数据库-选择执行Script(可以执行大文件)
- 选择我们准备好的.mysql文件
- 导入成功
- 欢迎路过的小哥哥小姐姐们提出更好的意见哇~~
备份导出数据
方案一:支持可以整个库导出、部分表导出、多个库导出(可选格式较少)
使用连接数据库
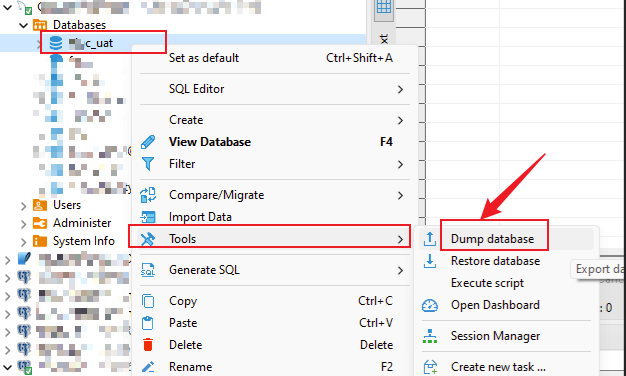
鼠标右键选择需要导出备份的数据库-工具-备份
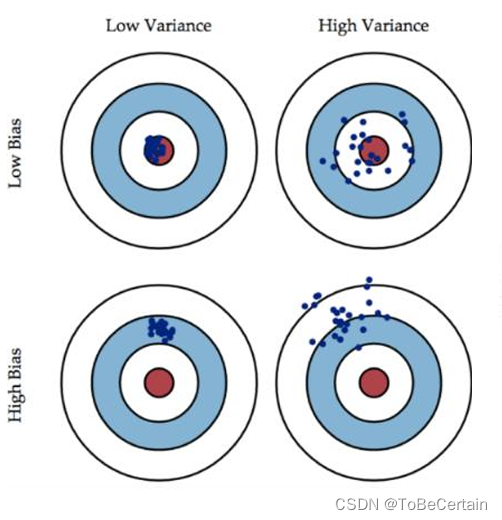
此步骤对于不同类型数据库来说,有的可以一次选择多个表,有的可以一次选择多个库,下面是两个截图案例
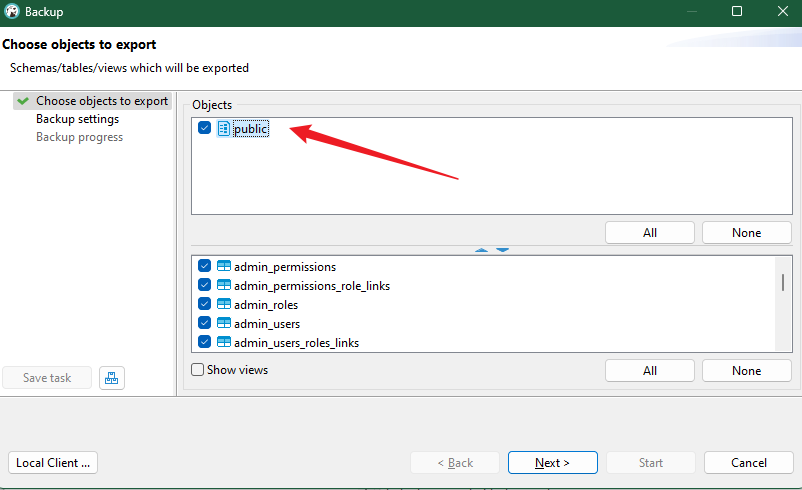
勾选需要导出的表-点击下一步
此步骤对于不同类型数据库来说,有的可以一次选择多个表,有的可以一次选择多个库,下面是两个截图案例
情况一:一次选择多个库

情况二:一次选择一个库,多个表
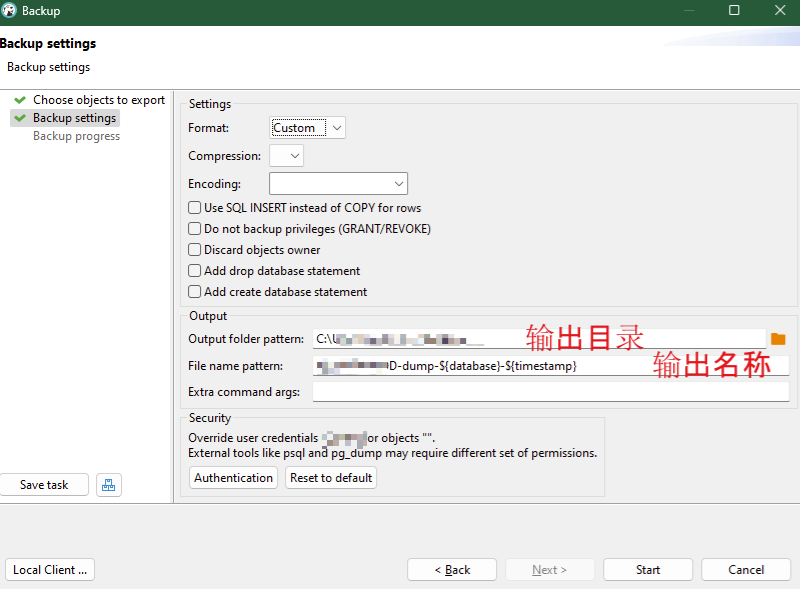
设置输出目录和输出名称-点击开始
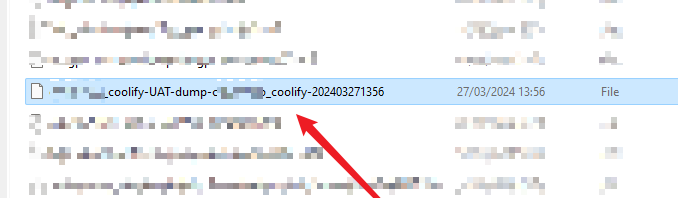
导出成功
方案二:导出备份单个表,以各种格式(可选格式较多)
选中某个表,单击鼠标右键-导出数据

选择你喜欢的格式
请注意,要先查看一下自己的导入库支持哪种导入格式再选
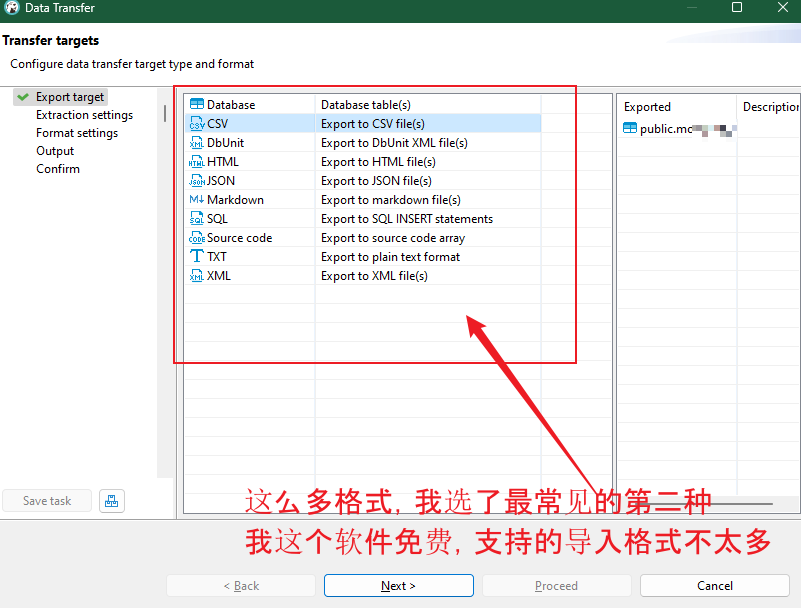
配置导出参数-自己配置哇~~
执行导出

导出成功

导入、恢复数据
我本人比较喜欢方案二和方案五,大家根据需求选择~
方案一:适合数据量小的情况
新建数据库,设置数据库名
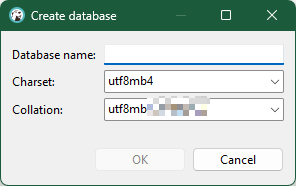
使用SQL编辑器进行创建表结构和数据导入
CREATE TABLE public.xiaojin (id bigserial NOT NULL,team_id varchar(50) NOT NULL,tmb_id varchar(50) NULL,data_id varchar(50) NULL
);执行语句
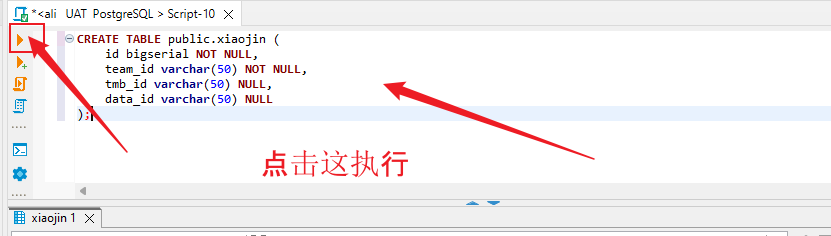
创建成功
执行插入数据语句
INSERT INTO public.xiaojin (id,team_id,tmb_id,data_id) VALUES ........方案二:批量导入单个数据库的多个表(会导致之前表数据被完全替换掉哦,注意提前备份数据)
如果新的服务器没有这个数据库,先创建数据库
右键点击需要导入的数据库-工具-导入
下面介绍两种不同的数据库的导入截图,mysql 和postgres

选择需要导入的文件
下面介绍两种不同的数据库的导入截图,mysql 和postgres


执行文件,导入成功
此处不再截图
方案三:单个导入某个表
这里使用我上面导出的那个csv格式文件进行导入单个表
选择需要导入的表,备份表
操作之前都要备份哦
选择需要导入的表,点击右键-导入数据

选择你文件的格式

执行导入
导入成功
如果报下面的错,是因为文件太大了,我们需要采用其他方案解决

Error auto mapping source table "test_data"Reason:
Error reading class info
Error reading class infoAn I/O error occurred while sending to the backend.An I/O error occurred while sending to the backend.EOFExceptionjava.io.EOFException方案四:导入大文件
下面以.sql文件举例大文件导入
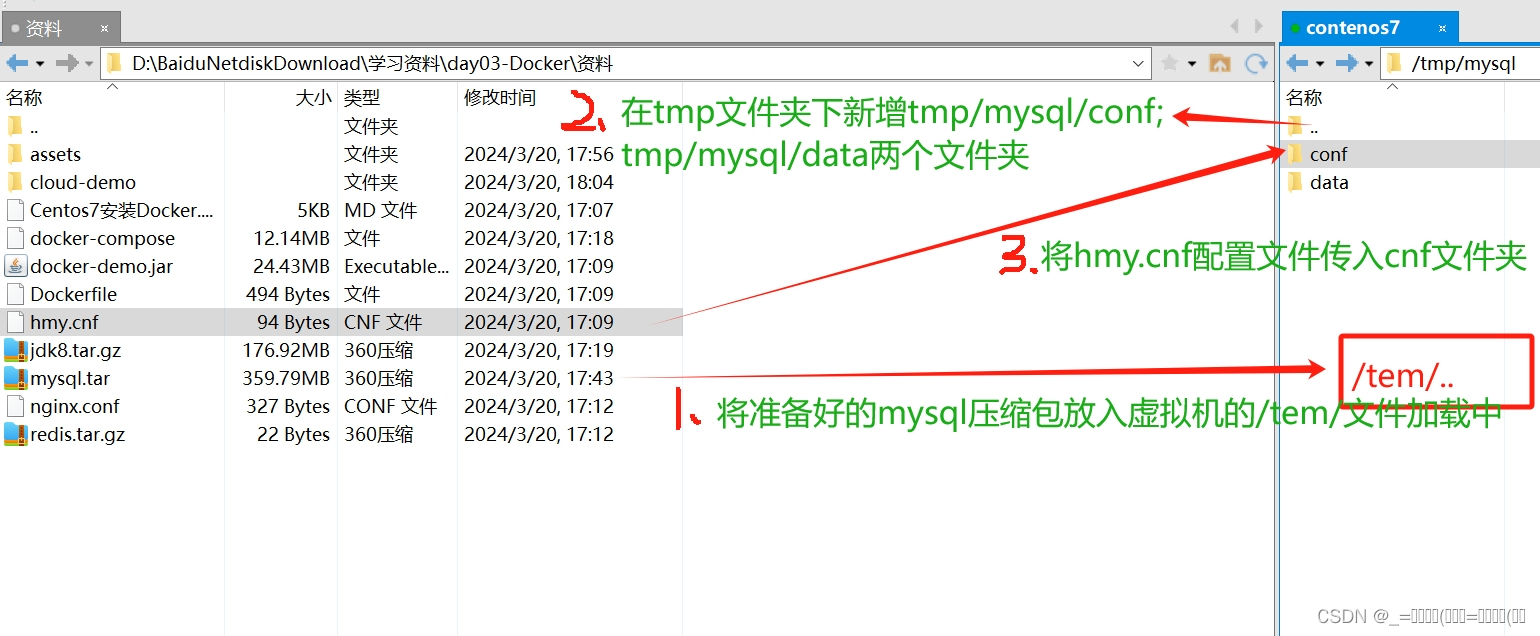
使用vscode打开需要导入的文件,确定我们准备的SQL文件编码格式
当然,其他工具也可以
点击项目

打开存放Scripts的文件夹,将我们的.sql拖进去

右键刷新
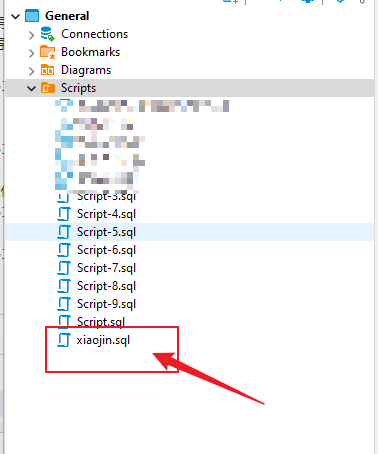
右键-属性-检查格式
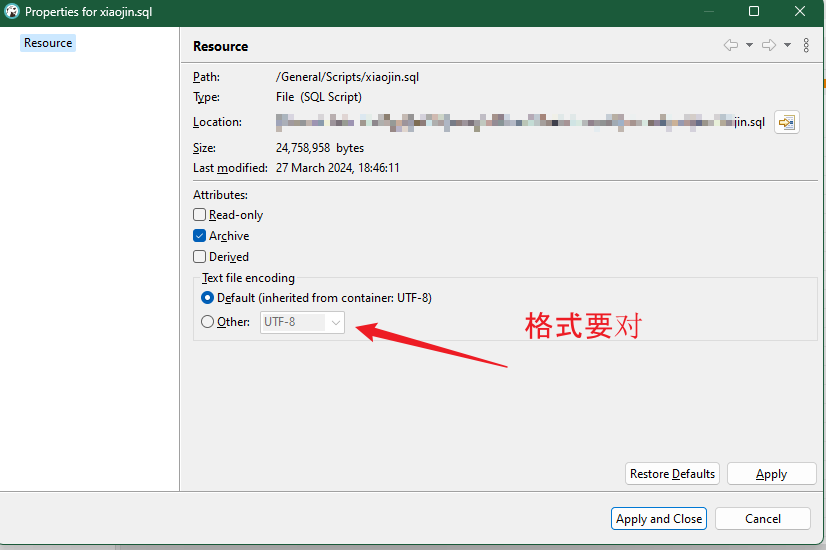
关联数据源


停留在项目下-连接-找到关联的数据源-右键-创建执行数据库任务
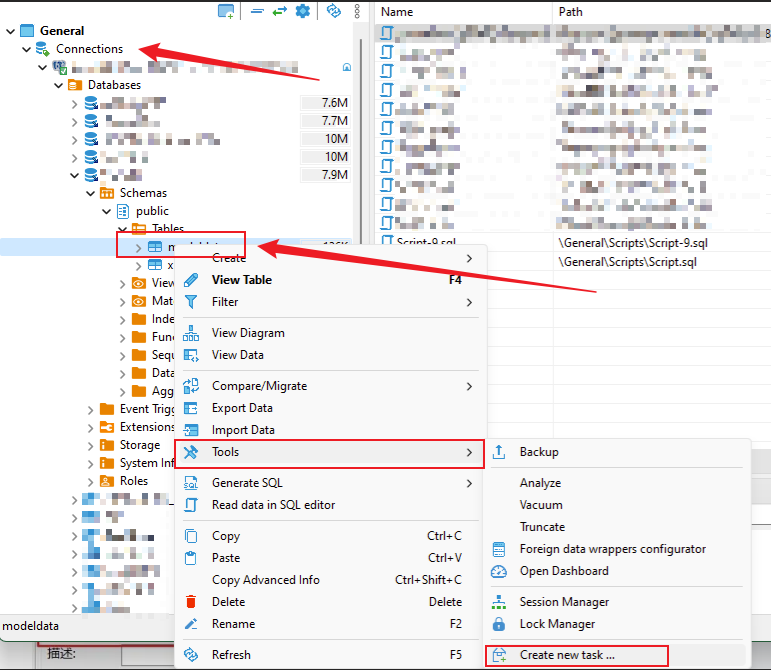
填写任务名称,选择执行脚本
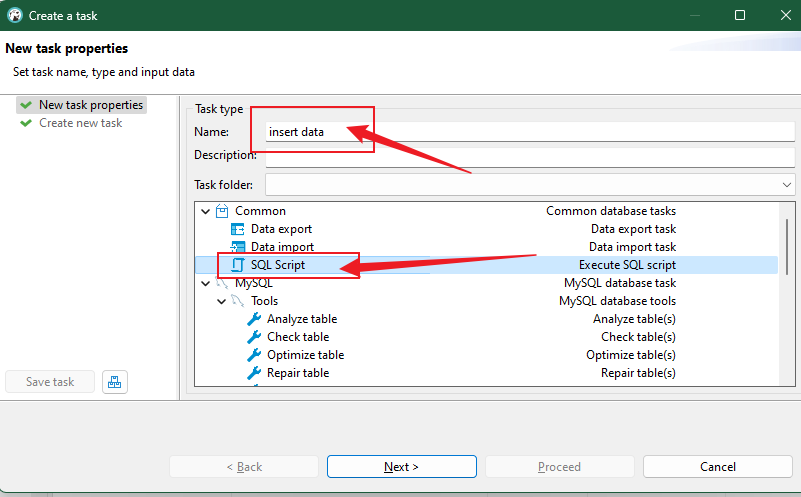
添加脚本

执行成功
如果这样还是不成功,可以参考方案五
方案五:最简单的执行sql方案(支持大文件)
选择项目-找到需要导入的数据库-选择执行Script(可以执行大文件)
只有在这里才可以执行大文件不会超出内存哦~~

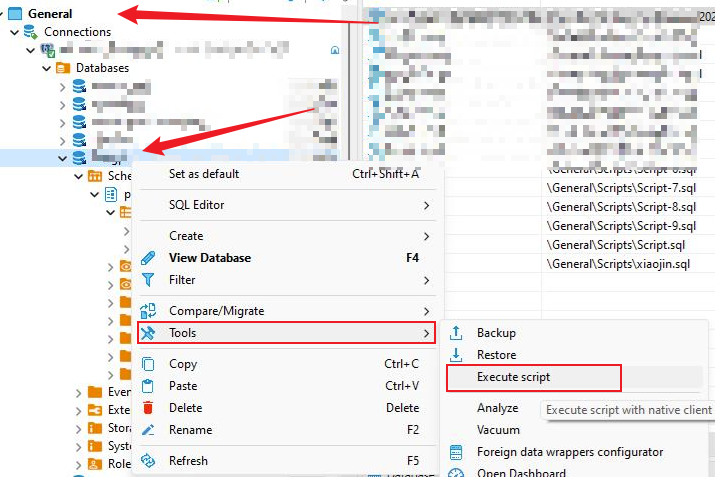
选择我们准备好的.mysql文件
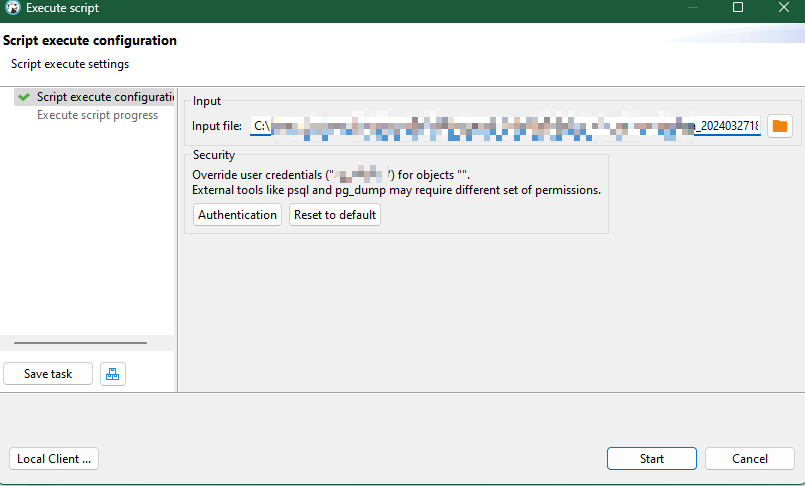
导入成功

- 今天就写到这里啦~
- 小伙伴们,( ̄ω ̄( ̄ω ̄〃 ( ̄ω ̄〃)ゝ我们明天再见啦~~
- 大家要天天开心哦
欢迎大家指出文章需要改正之处~
学无止境,合作共赢