目录
玫瑰图
数据格式
绘图基础
绘图升级(文本调整)
玫瑰图
下载数据data/2020/2020-11-24 · mirrors_rfordatascience/tidytuesday - 码云 - 开源中国 (gitee.com)
R语言绘图—南丁格尔玫瑰图 - 知乎 (zhihu.com)
数据格式
rm(list = ls())
library(ggplot2)
library(dplyr)
library(stringr)
hike_data <- readRDS("hike_data.rds")
hike_data$region <- as.factor(word(hike_data$location, 1, sep = " -- "))
hike_data$length_num <- as.numeric(sapply(strsplit(hike_data$length, " "), "[[", 1))plot_df <- hike_data %>%group_by(region) %>% ##按照region列进行分组summarise(sum_length = sum(length_num), mean_gain = mean(as.numeric(gain)),n = n()) %>% ##每个分组计算总长度(sum_length)、平均增益(mean_gain)和数量(n)mutate(mean_gain = round(mean_gain, digits = 0))#对mean_gain列进行舍入操作,保留0位小数
plot_df # A tibble: 11 × 4region sum_length mean_gain n<fct> <dbl> <dbl> <int>1 Central Cascades 2131. 2260 2262 Central Washington 453. 814 803 Eastern Washington 1334. 1591 1434 Issaquah Alps 383. 973 775 Mount Rainier Area 1602. 1874 1966 North Cascades 3347. 2500 3017 Olympic Peninsula 1700. 1572 2098 Puget Sound and Islands 810. 452 1919 Snoqualmie Region 1915. 2206 219 10 South Cascades 1630. 1649 193 11 Southwest Washington 825. 1185 123
绘图基础
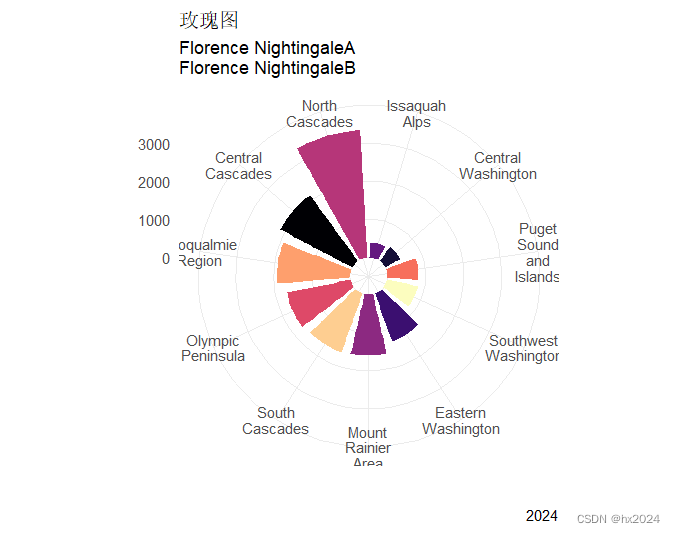
p1 <- ggplot(data = plot_df,aes(x = reorder(str_wrap(region, 5), sum_length),##x变量region,str_wrap()将region换行,按照sum_length排序y=sum_length,fill = region))+ ##fill = region 根据这个进行颜色填充geom_bar(width = 0.8,stat = "identity")+ #条形图coord_polar(theta="x",start=0)+ #坐标系 theta将角度映射到的变量(x或y)ylim(-500,3500)+ ##根据最大值设置合适的圆环直径scale_fill_viridis(option="A",discrete=T)+theme_minimal()+xlab(" ")+ylab(" ")+ ##主题labs(title = "玫瑰图", subtitle = paste( "Florence NightingaleA","Florence NightingaleB", sep = "\n"), caption = "2024")+theme(legend.position="none")##不展示图例
p1
dev.off()
绘图升级(文本调整)
计算角度
rm(list = ls())
library(ggplot2)
library(dplyr)
library(stringr)
library(viridis)
hike_data <- readRDS("hike_data.rds")
hike_data$region <- as.factor(word(hike_data$location, 1, sep = " -- "))
hike_data$length_num <- as.numeric(sapply(strsplit(hike_data$length, " "), "[[", 1))plot_df <- hike_data %>%group_by(region) %>% ##按照region列进行分组summarise(sum_length = sum(length_num), mean_gain = mean(as.numeric(gain)),n = n()) %>% ##每个分组计算总长度(sum_length)、平均增益(mean_gain)和数量(n)mutate(mean_gain = round(mean_gain, digits = 0))#对mean_gain列进行舍入操作,保留0位小数##需要对文本角度进行计算## 需要先进行排序计算
plot_df1 <- as.data.frame(plot_df)
##值从大到小降序排列
plot_df2 <- plot_df1[order(plot_df1$sum_length,decreasing=T),c(1:2)]
label_data<-plot_df2
library(data.table)
setDT(label_data)#构造文本
label_data[,new_label:=paste0(region,sum_length,"例")] ##添加文本内容
label_data[,id:=1:nrow(label_data)] ##添加排序号(已经降序排列)
number_of_bar <- nrow(label_data) ##行数量用于计算角度
label_data[,angle:=90 - 360 * (label_data$id-0.5) /number_of_bar] #角度计算
label_data[,":="(hjust=ifelse(angle<90,1,0),angle1=ifelse(angle<90,angle+180,angle))] head(label_data)[1:3]region sum_length new_label id angle hjust angle1 1: North Cascades 3346.53 North Cascades3346.53例 1 73.636364 1 253.6364 2: Central Cascades 2130.85 Central Cascades2130.85例 2 40.909091 1 220.9091 3: Snoqualmie Region 1915.32 Snoqualmie Region1915.32例 3 8.181818 1 188.1818
p1 <- ggplot(data = plot_df,aes(##一定注意reorder(str_wrap(region, 5), sum_length,decreasing=T)顺序与计算角度顺序需要一致x = reorder(str_wrap(region, 5), sum_length,decreasing=T),##x变量region,str_wrap()将region换行,按照sum_length排序y=sum_length,fill = region))+ ##fill = region 根据这个进行颜色填充geom_bar(width = 0.8,stat = "identity")+ #条形图coord_polar(theta="x",start=0)+ #坐标系 theta将角度映射到的变量(x或y)ylim(-500,3500)+ ##根据最大值设置合适的圆环直径scale_fill_viridis(option="A",discrete=T)+theme_minimal()+xlab(" ")+ylab(" ")+ ##主题labs(title = "玫瑰图", subtitle = paste( "Florence NightingaleA","Florence NightingaleB", sep = "\n"), caption = "2024")+theme(legend.position = "none", #不展示图例text = element_text(color = "gray12", family = "Bell MT"), #参数https://www.jianshu.com/p/8e33dc11ed8caxis.text = element_blank(), axis.title = element_blank(), panel.grid = element_blank())+ geom_text(data=label_data, aes(x=id, y= sum_length, label=new_label, hjust=hjust), color="black", fontface="bold", alpha=0.6, size=3.5, angle=label_data$angle1,inherit.aes=FALSE)
p1
dev.off()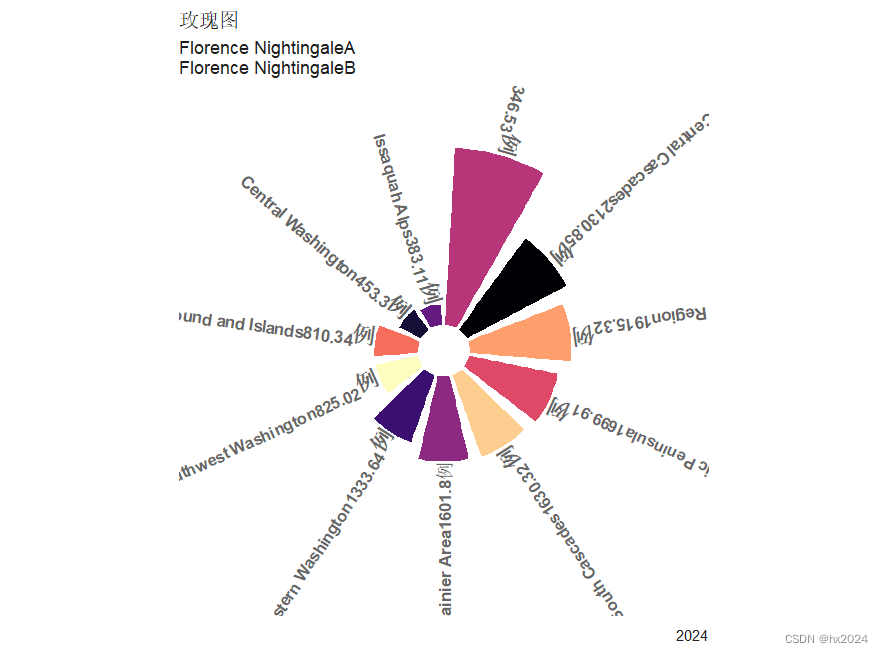
参考:
1:南丁格尔玫瑰图 With ggplot2【R语言】_r语言玫瑰图-CSDN博客
2:R语言绘图—南丁格尔玫瑰图 - 知乎 (zhihu.com)
雷达图学习:R实战| 雷达图(Radar Chart)-CSDN博客