目录
prompt 工程是什么?
案例
vllm 推理加速框架
prompt 工程是什么?
prompt:提示词,也就是我们使用网页版输入给大模型的内容就叫 prompt,那什么是 prompt 工程呢?
简单理解其实就是利用编写的 prompt 去让大模型完成我们想要完成的任务,一般网页版本的都是多轮对话,通过多轮对话完成想要实现的事情也是一种 prompt 的使用;
另外一种是在实际业务中的使用,实际业务中到底怎么使用 prompt 呢?
prompt 工程 = prompt + 算法,这里的算法并不是指什么高升算法,是指通过编程解析大模型的输出,以及结合一些工具预处理文本这方面的编程代码。
prompt 入门门槛我觉得比较低,网上随便找资料大概都知道编写模版套路,但效果得结合实际业务情况调优好几天,有些还得通过编程进行辅助,比如预处理工具,提取地名啥的,匹配标签啥的,再去输入给大模型。
总结来说入门低,但要想在业务中用好,也没那么容易。
案例
我找了一个案例来说明下完整的 prompt 工程到底是在干啥,
模型:qwen-7b-chat
显存:24G
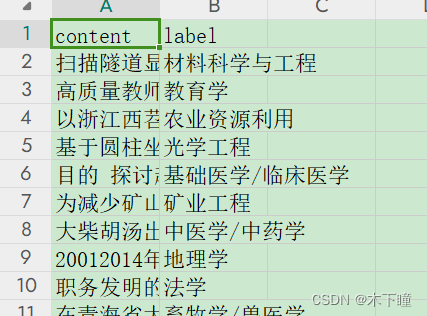
数据,专业描述的文本,还有对应的 label,
任务:通过编写 prompt ,传入专业列表,让大模型去判断是哪个专业
评判标准:其实就是文本分类任务,已经有数据标注了,让大模型预测出来后,计算准确率就可以评判效果好不好
数据链接:https://pan.baidu.com/s/1EvvNSWb9RXQm4TqHeg52fA
提取码:2jh3
链接:https://pan.baidu.com/s/1fdNsI35eiQAPsiIDeaTsAQ
提取码:6mem
直接给代码:
import pandas as pd
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import time# 加载词表,模型,配置
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp",trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp",device_map="auto",trust_remote_code=True).eval()
model.generation_config = GenerationConfig.from_pretrained("/root/autodl-tmp",trust_remote_code=True,temperature=0.6) # 可指定不同的生成长度、top_p等相关超参def prompt_predit(content, labels):"""prompt 预测 content 属于哪个类别"""prompt = f"""【学科分类解析】
角色设定:
作为一名资深学者,对各个专业有着深入的了解,擅长通过描述精准判断出是哪一个专业,你的任务是从给定的专业列表中找出与描述最相关的10个专业。已知条件:
[描述]: {content}
[专业列表]: {labels} 决策规则:
1. 专业必须来源于[专业列表]列表;
2. 描述中的专业名词是否指向特定的专业,例如:“数据库=》计算机科学与技术”;
3. 从描述中抽取出关键专业术语,对比`[专业列表]`内的专业名称及其涵盖范围,寻找紧密相关的匹配项。要求:
- 请直接输出专业,无需解释说明;
- 不得拒绝回答;
- 当描述中明确指向某个特定专业时,优先选择该专业;
- 若描述较为模糊或包含多个专业元素,需根据专业知识和经验作出最佳推断。输出格式严格按照列表格式输出:
[专业1, 专业2, 专业3......]
"""response, history = model.chat(tokenizer, prompt, history=None)return response.replace('\n', '').replace(' ', '')if __name__ == '__main__':data = pd.read_csv('../output/classfield_data.csv')data = data.head(100)with open('../data/分类提取/labels_all.txt', 'r', encoding='utf8') as f:labels = f.readlines()res = []start_time = time.time()for index, row in data.iterrows():content = row['content']label = row['label']print(f'---------- {index + 1} / {len(data)} -----------')print(f'当前 content:{content} 正确 label:{label}')try:response = prompt_predit(content, labels)except Exception as e:response = str(e)print(f'解析错误:', response)print(f'预测结果:', '=>', response)res.append(response)data['llm_res'] = res# data['correct'] = (data['llm_res'] == data['label'])data['correct'] = data.apply(lambda row: True if row['label'] in row['llm_res'] else False, axis=1)print(f'预测正确率:', round(sum(data['correct']) / len(data) * 100, 2))data.to_excel('../output/classfield_data_predit.xlsx', index=False)end_time = time.time()print(f'用时:{end_time - start_time}')
这是最简单可以说明什么是 prompt 工程的案例,下面来讲一下思路。
1、加载模型
2、读入要处理的数据
3、把要传递给大模型的数据拿出来(content,labels)
4、调用大模型,prompt 编写好再去调用
5、如果需要,需要单独编写解析大模型返回的解析结果
6、最后保存所有结果
以上就是 prompt 工程整体流程,可以看出流程还是挺简单的,但想要想过真的没那么容易,有几方面:
1、不同模型,想通 prompt 效果不一样
2、不同词语描述,效果也不一样
3、哪怕改一个字,效果也会不一样
所以 prompt 要说什么技巧套路,我觉得有点扯淡,基本模版的技巧大家看了都会,但想要效果好得不停地调。
而且评判的数据挺重要的,就像我这个需求应该是分类任务对吧,那结果应该有一个,对就对,不对就不对,我调了几版 prompt ,最好的准确率是 39%,就去数据及理由,有些数据光是人去判断都不太好判断,或是有歧义的,更别说模型了,例如
content:20012014年对青海省主要水体中外来鱼类组成、分布和生态习性进行了系统调查。野外调查采集到外来鱼类30种,隶属6目12科25属,已建群外来鱼类16种。其中,黄河水系拥有的外来鱼类最多,共26种;长江上游有4种,为该河段首次记录;可鲁克湖12种,是内陆水体中外来鱼类最多的水域。结合历史文献记录,截至2013年,全省记录外来鱼类7目13科31属36种,已远超土著鱼类物种数(50种和亚种)的一半。调查分析发现外来鱼类呈现数量持续增多、分布范围向高海拔扩张的趋势。已建群外来鱼类主要是分布于我国东部平原地区的广布型物种。虹鳟( Oncorhynchus myskiss)是代表性外来种,现已在黄河上游干流部分河段形成自然繁殖群体,其食物组成包括水生无脊椎动物和高原鳅等土著鱼类。建立水产种质资源保护区和开展外来鱼类影响研究是防控高原地区外来鱼类的必要措施。 正确 label:地理学这段文本大家可以看看觉得他是在描述什么专业,我看了后觉得跟水产有关,大模型预测结果也是水产:
预测结果: => [水产|根据描述中提到的“外来鱼类”、“黄河水系拥有最多外来鱼类”、“已在黄河上游干流部分河段形成自然繁殖群体”等内容,可以推断出描述涉及的是水产专业。]再去看数据标注的答案,摸不着头脑,可能从描述看最相关的水产,其次再是地理学之类的,
所以我改了 prompt ,选出10 个专业,只要 label 再里面就算对,准确率直接就 67 了。
所以标注的数据也挺重要的。
vllm 推理加速框架
上面我们通过一个最基本的案例明白了什么是 prompt 工程,现在来看一个框架 vllm ,是推理加速用的,意思就是说加速模型生成的速度。
把上面的代码改为 vllm 框架,改用批次,最大化利用 gpu 效率,利用 1000 条来测试一下速度有多少提升
from vllm import LLM, SamplingParams
import os
import time
import pandas as pdos.environ['CUDA_VISIBLE_DEVICES'] = '0'
model_path = "/root/autodl-tmp"
llm = LLM(model=model_path, trust_remote_code=True, tokenizer=model_path, tokenizer_mode='slow', tensor_parallel_size=1)
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)def batch_prompt(cur_batch_data):prompts = []for index, row in cur_batch_data.iterrows():content = row['content']prompt = f"""【学科分类解析】
角色设定:
作为一名资深学者,对各个专业有着深入的了解,擅长通过描述精准判断出是哪一个专业,你的任务是从给定的专业列表中找出与描述最相关的个专业。已知条件:
[描述]: {content}
[专业列表]: {labels} 决策规则:
1. 专业必须来源于[专业列表]列表;
2. 描述中的专业名词是否指向特定的专业,例如:“数据库=》计算机科学与技术”;
3. 从描述中抽取出关键专业术语,对比`[专业列表]`内的专业名称及其涵盖范围,寻找紧密相关的匹配项。要求:
- 请直接输出专业,无需解释说明;
- 不得拒绝回答;
- 当描述中明确指向某个特定专业时,优先选择该专业;
- 若描述较为模糊或包含多个专业元素,需根据专业知识和经验作出最佳推断。输出:
[专业]
"""prompts.append(prompt)return promptsif __name__ == '__main__':data = pd.read_csv('../output/classfield_data.csv')data = data.head(1000)with open('../data/分类提取/labels_all.txt', 'r', encoding='utf8') as f:labels = f.readlines()global_time = 0batch_size = 32res = []for i in range(0, len(data), batch_size):cur_start_time = time.time()cur_batch_data = data[i:i + batch_size]cur_batch_prompt = batch_prompt(cur_batch_data)outputs = llm.generate(cur_batch_prompt, sampling_params)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textres.append(generated_text)cur_end_time = time.time()global_time += cur_end_time - cur_start_timeprint(f'当前批次用时 {cur_end_time - cur_start_time} 目前已使用使用时间 {global_time} 进度 {i + batch_size}')data['llm_res'] = res# data['correct'] = (data['llm_res'] == data['label'])data['correct'] = data.apply(lambda row: True if row['label'] in row['llm_res'] else False, axis=1)print(f'预测正确率:', round(sum(data['correct']) / len(data) * 100, 2))data.to_excel('../output/classfield_data_predit.xlsx', index=False)print(f'总用时:{global_time}')
vllm 用时
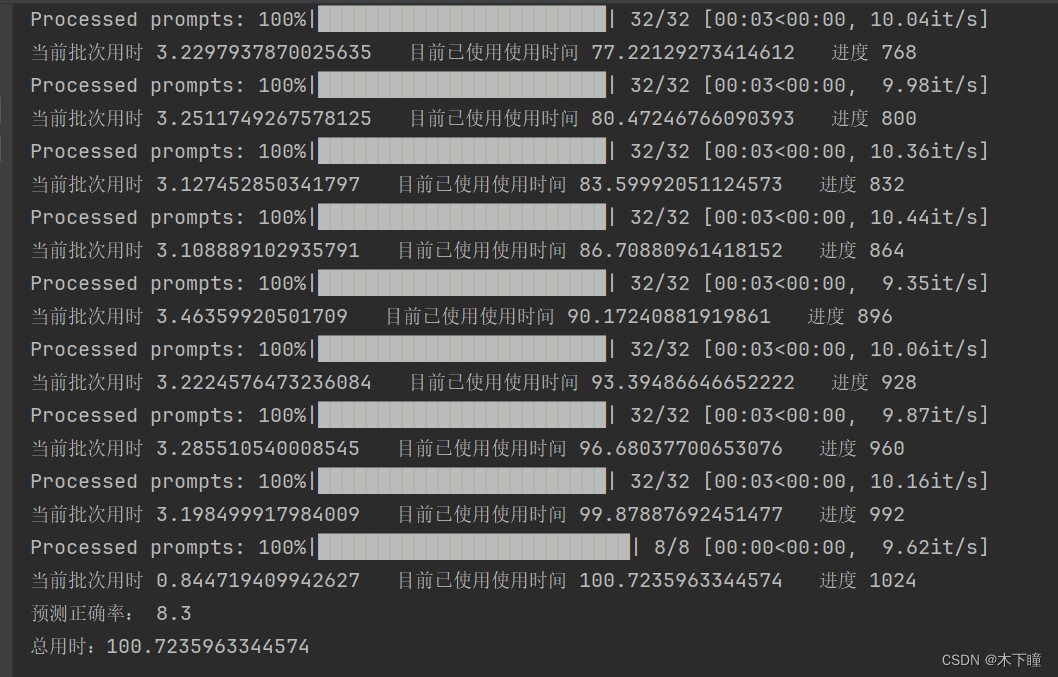
之前的代码用时:

可以看出,真的能像网上说的那样提速 2 倍左右,但准确率下降了,我把输出打印出来看,发现是输出内容没有按照之前的来了,说明 vllm 会对输出有影响。至于原因可以参考一下别人的分析:LLM推理4:vllm和HF推理结果不一致 - 知乎

![【PyTorch][chapter 25][李宏毅深度学习][Transfer Learning-1]](https://img-blog.csdnimg.cn/direct/d5d899d446d8499a83839a2eef7611e9.png)
