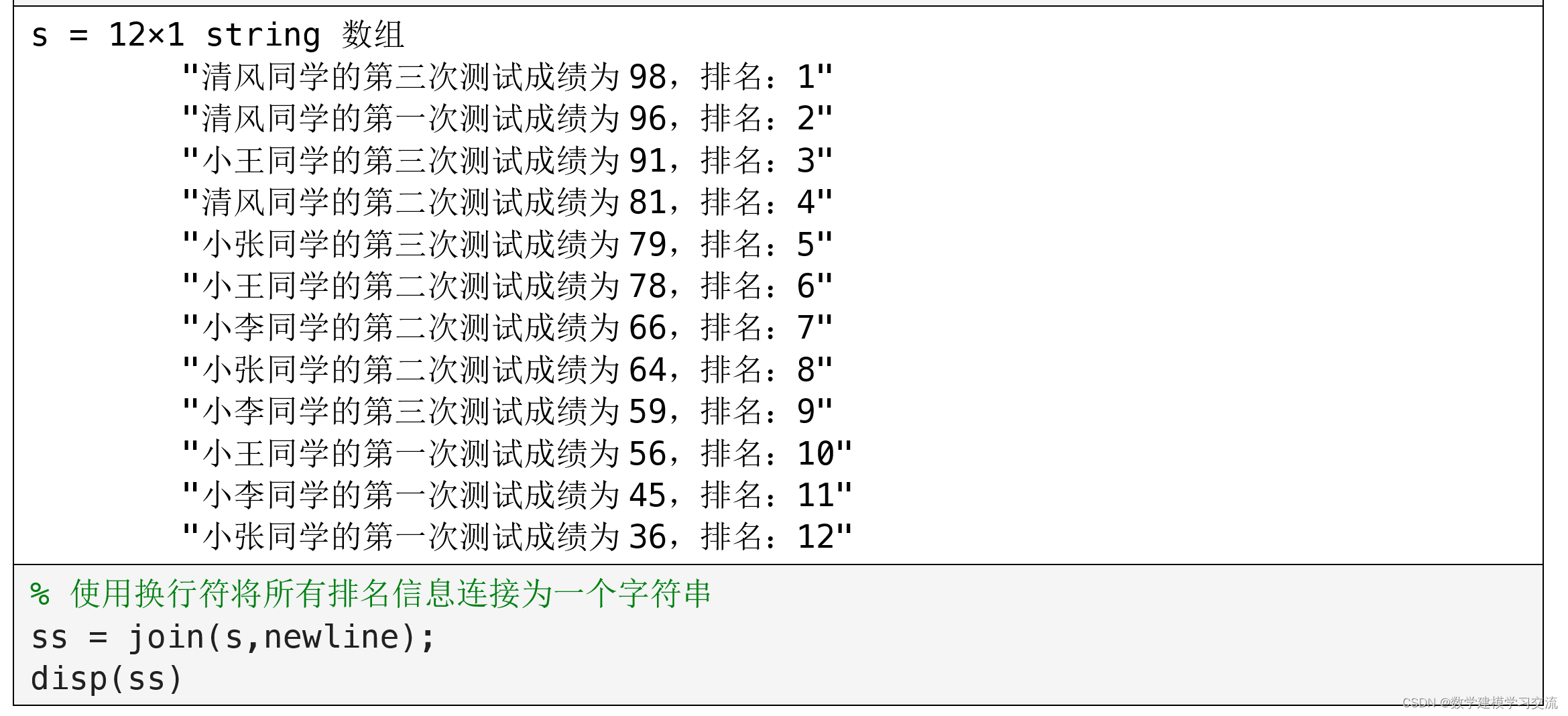
1. 大数据架构全景

Data Sources 数据来源
所有大数据解决方案都始于一个或多个数据源。例如:
- 应用程序数据存储,如关系型数据库。
- 应用程序生成的静态文件,如Web服务器日志文件。
- 实时数据源,如物联网设备。
Data Storage数据存储
批处理操作所需的数据通常存储在分布式文件存储中,该存储可以以各种格式容纳大量大型文件,这种类型的存储常被称为数据湖。
- Hadoop Distributed File System (HDFS): 开源的分布式文件系统,广泛用于大数据生态系统中,是构建本地数据中心数据湖的核心存储层。
- Apache Hudi或 Apache lceberg: 这两个开源项目提供了高级的表格式存储管理,具备事务性和数据版本控制等功能,可以构建在HDFS或其他云存储之上形成数据湖。
- OpenStack Swift或Ceph: 这些开源的对象存储系统在一定程度上可以模拟云存储服务,并与大数据分析工具集成创建数据湖环境。
Batch Processing批处理
由于数据集非常庞大,通常大数据解决方案必须使用长时间运行的批处理作业来过滤、聚合并准备数据用于分析。这些作业通常涉及读取源文件、处理它们并将输出写入新文件
- Spark则是一个更快、更通用的执行引擎,支持SQL查询(Spark sQL)、流处理(Spark Streaming)、机器学习(Mlib)等。
- Apache Hive提供了一种SQL-like接口(HiveQL)以方便用户在Hadoop上执行批处理查询,它将SQL查询转化为MapReduce作业,进行大规模数据处理。
- Apache Pig提供了一种高级数据流语言——Pig Latin,使得开发者能够更容易编写复杂数据转换流水线,执行批处理任务。
- Apache Flink ——一个开源流处理和批处理框架,支持事件时间窗口、状态管理以及精确一次语义等高级流处理特性。
Real Time Message Ingestion实时消息摄取
实时消息摄取:如果解决方案包含实时数据源,则架构必须包含一种方式来捕获和存储实时消息以便进行流处理。这可能是一个简单的数据存储,其中传入的消息被放入一个文件夹等待处理。然而,许多解决方案需要一个消息摄取存储作为消息缓冲区,并支持扩展性处理、可靠交付和其他消息队列语义。
- Flink CDC主要用于捕获数据库中的实时变化数据〈如INSERT、UPDATE、DELETE操作),并将这些变化以消息的形式传输至下游系统,例如消息队列(如Kafka)、数据湖〈如Hadoop、HDFS)或其他数据存储与处理系统。在这个过程中,Flink CDC扮演了一个实时数据采集和预处理的角色,确保数据变更能够以近实时的方式被下游消费者消费或进一步分析。
- Apache Kafka-开源分布式流处理平台,它能够以发布-订阅模式处理大量实时数据流,并且提供持久化存储。
- Apache Pulsar-分布式消息流平台,具有水平扩展、低延迟和持久化的特性,类似于Kafka,但设计上采用了多租户和分层存储架构。
Stream Processing流处理
捕获实时消息后,解决方案必须通过过滤、聚合等方式对它们进行处理,从而为分析做好准备。经过处理的流数据随后会被写入输出接收器。
- Apache Storm ——分布式、容错实时计算系统,用于处理大量数据流。
- Apache Flink ——一个开源流处理和批处理框架,支持事件时间窗口、状态管理以及精确一次语义等高级流处理特性。
- Apache Spark Streaming ——Apache Spark提供了对实时数据流处理的支持,可以在同一个引擎上统一处理离线批处理和实时流数据。
- Kafka Streams ——基于Apache Kafka的客户端库,允许开发者编写应用程序进行流处理。
Analytical Data Store分析数据存储
许多大数据解决方案会准备数据进行分析,并将处理后的数据以结构化格式提供给分析工具查询。用于服务于这些查询的分析数据存储可以是KimbalI风格的关系型数据仓库,这是大多数传统商业智能(BI)解决方案所采用的。另外,数据也可以通过低延迟NoSQL技术〈如HBase)或提供分布式数据存储中数据文件元数据抽象的交互式Hive数据库呈现。Azure Synapse Analytics提供了大规模云端数据仓库的托管服务。HDInsight支持Interactive Hive、HBase和Spark SQL,这些同样可用于为分析提供数据服务。
- Apache Presto: 高速、分布式的SQL查询引擎,专为交互式分析设计,能够跨越多个数据源实现PB级别数据的即时查询。
- Doris: 实时OLAP数据库系统,提供高并发、低延迟的SQL查询能力,尤其适用于企业级的实时数据分析场景。
- Clickhouse: 高性能列式数据库管理系统,专注于在线分析处理(OLAP)查询,能够在大数据集上实现亚秒级响应速度。
- Apache HBase: 基于Hadoop的分布式、面向列族的NoSQL数据库,支持海量数据的随机、实时读写访问,适用于大数据存储和实时分析。
- Apache Druid: 为实时和批量数据设计的列式存储、实时OLAP分析数据库,特别优化了对时间序列数据的快速摄取和查询性能。
Analytics And Reporting分析与报告
大多数大数据解决方案的目标是通过分析和报告为用户提供关于数据的洞察。为了赋能用户分析数据,架构可能包括数据建模层,如多维OLAP立方体或Azure Analysis Services中的表格数据模型。
它也可能支持自助式Bl,利用Microsoft Power BI或Microsoft Excel中的建模和可视化技术。分析和报告还可以采取数据科学家或数据分析师进行交互式数据探索的形式。对于这些场景,许多Azure服务支持分析笔记本,如Jupyter,使这些用户能够利用他们现有的Python或R技能。对于大规模数据探索,您可以使用独立部署或与Spark配合使用的Microsoft R Server。
Orchestration编排
大数据架构中的Orchestration层是整个体系中的关键管理层,它的核心作用在于对大数据平台中的各种组件和服务进行统一调度、协调和管理,以实现跨系统、跨进程的自动化部署、任务编排和资源优化。这一层能够帮助组织有效地管控复杂的分布式环境,包括但不限于作业调度、资源分配、服务注册与发现、状态监控、故障恢复以及动态配置管理等。通过Orchestration层,可以简化大数据系统的运维复杂性,提高整体效率和可靠性。
- Apache Airflow:提供了一个可编程的工作流管理平台,便于定义、调度和监控数据处理管道。
- Apache 0ozie:专为Hadoop生态系统设计的任务调度系统,能够协调多个Hadoop任务及其依赖关系。
本节摘自
【【IT老齐484】大数据架构全景与技术选型】 https://www.bilibili.com/video/BV1V2421N7hj/?share_source=copy_web&vd_source=2966a7cdd1b63288e88160ee3b627669
2.Lambda架构
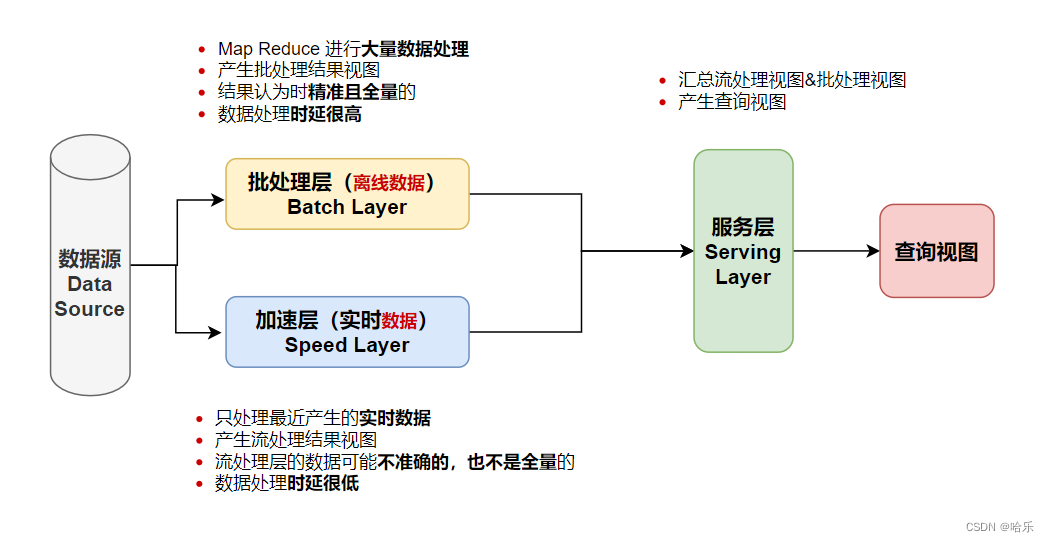
如下图所示,Lambda架构可分解分为批处理层、加速层和服务层三层。
2.1.批处理层
核心功能:存储数据集和生成Batch View。
该层负责管理主数据集,主数据集中的数据必须具备以下三个属性:
(1)数据是原始的。(2)数据是不可变的。(3)数据永远是真实的。
2.2. 加速层
对加速层批处理视图建立索引,便于能快速进行即席查询(Ad Hoc Queries)。它存储实时视图并处理传入的数据流,以便更新这些视图。Speed Layer和 Batch Layer比较类似。Speed Layer对数据进行计算并生成Realtime View,其主要区别在于:
- Speed Layer处理的数据是最近的增量数据流,Batch Layer处理的全体数据集。
- Speed Layer为了效率,接收到新数据时不断更新Realtime View,而 Batch Layer根据全体离线数据集直接得到Batch View。
2.3. 服务层
Lambda架构的Serving Layer用于响应用户的查询请求,合并 Batch View和Real-time View中的结果数据集到最终的数据集。该层提供了主数据集上执行的计算结果的低延迟访问。读取速度可以通过数据附加的索引来加速。
2.4. Lambda架构的实现

如图所示,在这种Lambda架构实现中,Hadoop(HDFS)用于存储主数据集, Spark(或Storm)可构成速度层(Speed Layer),HBase(或Cassandra)作为服务层,由Hive创建可查询的视图。
- Kafka 是由
Linkedin公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。 - Hadoop是被设计成适合运行在通用硬件上的分布式文件系统(Distributed File System)。HDFS是一个具有高度容错性的系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
- Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC BerkeleyAMP lab所开源的类Hadoop Map Reduce的通用并行处理框架,Spark拥有Hadoop Map Reduce所具有的优点;但不同于Map Reduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的 Map Reduce算法。
- HBase - Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
2.5 Lambda架构的优缺点
1.优点
(1)容错性好。Lambda 架构为大数据系统提供了更友好的容错能力,一旦发生错误,我们可以修复算法或从头开始重新计算视图。
(2)查询灵活度高。批处理层允许针对任何数据进行临时查询。
(3)易伸缩。所有的批处理层、加速层和服务层都很容易扩展。因为它们都是完全分布式的系统,我们可以通过增加新机器来轻松地扩大规模。
(4)易扩展。添加视图是容易的,只是给主数据集添加几个新的函数。
2.缺点
(1)全场景覆盖带来的编码开销。
(2)针对具体场景重新离线训练一遍益处不大。(3)重新部署和迁移成本很高。
3. Kappa架构
Kappa架构的原理就是:在Lambda的基础上进行了优化,删除了Batch Layer的架构,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次则可。Kappa数据处理架构如图所示。
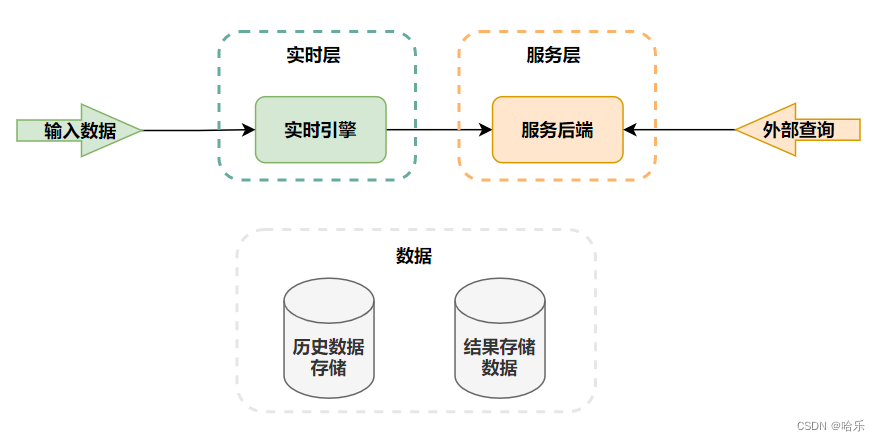 从使用场景上来看,Kappa架构与Lambda相比,主要有两点区别:
从使用场景上来看,Kappa架构与Lambda相比,主要有两点区别:
(1) Kappa不是Lambda的替代架构,而是其简化版本,Kappa放弃了对批处理的支持,更擅长业务本身为增量数据写入场景的分析需求,例如各种时序数据场景,天然存在时间窗口的概念,流式计算直接满足其实时计算和历史补偿任务需求;
(2) Lambda直接支持批处理,因此更适合对历史数据分析查询的场景,比如数据分析师需要按任意条件组合对历史数据进行探索性的分析,并且有一定的实时性需求,期望尽快得到分析结果,批处理可以更直接高效地满足这些需求。
3.1 Kappa架构的优缺点
Kappa 架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题,避免了Lambda架构中与离线数据合并的问题,查询历史数据的时候只需要重放存储的历史数据即可。
Kappa的缺点:
(1)消息中间件缓存的数据量和回溯数据有性能瓶颈。
(2)在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
(3) Kappa在抛弃了离线数据处理模块的时候,同时抛弃了离线计算更加稳定可靠的特点。Lambda虽然保证了离线计算的稳定性,但双系统的维护成本高且两套代码带来后期运维困难。